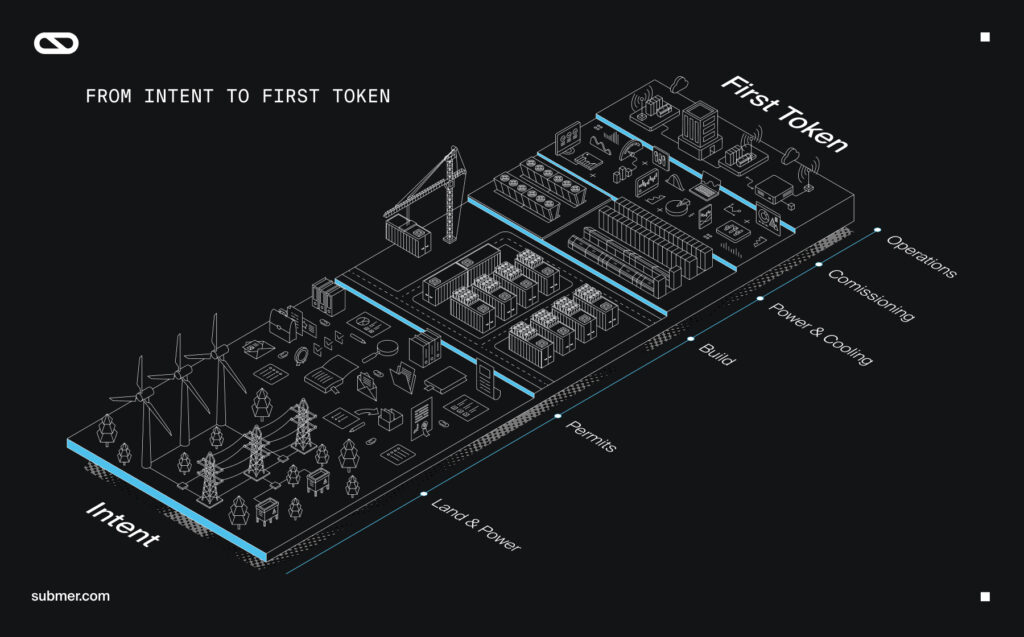
AI adoption is accelerating at a pace few infrastructure cycles were designed to match. The global AI data center market is now growing at roughly 25–30% annually, pushing capacity from hundreds of billions toward the trillion‑dollar scale within this decade. With growing demands for GPU and AI services, the bottleneck has shifted with the same recurring gaps: intent moves fast but actual deployment does not. Racks arrive before power supply is ready. Facilities are designed for hardware that cant keep up with the growing compute needs. Projects look healthy on paper while production tokens are months if not years away.
In this new AI era, traditional data center metrics have shifted. It is no longer about the capacity of the data center, it is about how quickly production-grade compute can be commissioned, cooled, deployed and operated reliably.
The most useful KPI today is not megawatts installed or racks delivered. It is Time to Token (TTT); a practical, execution-first metric that measures the journey from intent to real output. And for the next wave of AI infrastructure; from hyperscale campuses to edge inference nodes, TTT will increasingly separate fast movers from long lead-time projects across regions.
What “Time to Token” really means
Time to Token, or TTT, measures the elapsed time from plan and purchase order to the first tokens generated on production GPUs. It captures the full journey: power readiness, permitting, logistics, installation, cooling integration, commissioning, and operational handover. In today’s AI deployments, that journey typically runs between 24 to 36 months – and sometimes longer if the delivery is fragmented across various vendors.
Why define it this way? Because AI value is realized only when infrastructure is in production. A campus that’s “under construction” does not produce outcomes; a rack “on order” does not generate tokens; and a hall that’s “nearly ready” won’t meet SLA expectations until commissioning is complete. TTT shifts the focus from announced capacity to operational output.
Why a Time to Token mindset matters now
The timing of the TTT shift is not accidental. AI demand is accelerating through the second half of the decade, driven by cloud growth, AI workloads and sovereign AI initiatives. At the same time the constraints look increasingly similar across the board.
- Power availability and timelines are the gating factor, not floor space
- Permitting / planning approvals remains a critical path item
- Hardware and supply chain volatility can turn a “designed” facility into an outdated one before it goes live.
- Sustainability requirements (energy, water, carbon reporting, and efficiency) are moving from “nice to have” to non-negotiable.
- AI deployment is shifting beyond a few core hubs toward a core-to-edge footprint for low-latency inference and data proximity.
At Submer Group, we believe that the key differentiator will be speed and scale. AI infrastructure is no longer limited to just hyperscaler hubs. Inference workloads today are extending beyond cloud facilities and outward into metros, regional and edge locations. This shift increases complexity and coordination risks, making TTT even more relevant.
Why traditional data center timelines don’t fit the AI lens
The pain points and delays become clearer when you look at where TTT is actually lost. Historically, data centers take between 24 to 36 months from planning to full operations. In the current AI landscape, that timeline is a strategic liability.
AI data center projects stretch because delivery is broken into disconnected stages: land and power negotiations, facility design, construction, MEP integration, cooling, IT deployment, commissioning, then extension to edge nodes and connectivity. Each stage is often owned by a different party. Every handoff introduces delays. Every redesign compound risks. TTT expands not because teams are slow, but because the system is fragmented.
This friction is magnified by the nature of AI hardware as well. Today’s AI racks generally operate in the 50 to 150 kilowatt range with higher compute and density requirements emerging quickly. This is not a digital environment that tolerates late design changes, cooling retrofits, or commissioning surprises. When density, power, and thermal decisions are made in silos, delays are inevitable and tokens slip further into the future.
Reducing Time to Token requires changing how infrastructure is delivered, not just accelerating individual steps. Submer Group’s perspective is clear: the “traditional build cycle” doesn’t work through an AI lens, and the answer lies in modular and scalable delivery models.
Modularity: one of the fastest levelers for AI datacenters
TTT is best understood as a chain, most delays happen at predictable points like power, permits, logistics etc. Modularity is how you remove friction from said chain.
By shifting construction and integration off-site, modular systems built on reference designs will allow site preparation and manufacturing to occur simultaneously. Reference designs replace bespoke builds thereby reducing design churns. Commissioning becomes predictable because systems are deployed using known patterns rather than being reinvented for every project.
Modular design also supports a crucial AI reality: infrastructure compute requirements shift fast. By using repeatable modules, customers can start small with lower initial investment, scale incrementally, and adapt infrastructure as AI workloads evolve. Whether the DC expansion is multi-city (metro plus Tier-II), modularity is how organizations can replicate quality and performance consistently across locations.
Full-stack AI infrastructure: the operating model that makes TTT achievable
The biggest TTT gains often come from the operating model, not from any single technology. AI infrastructure is often delivered like a relay race, with different vendors responsible for advisory, build, MEP, IT and operations. Coordination becomes the customer’s burden. Accountabilities diffuse and timelines slip as a result.
An end-to-end full stack delivery model like Submer Group changes that equation, giving enterprises and governments greater ownership and control of their AI capabilities while reducing execution-slowing dependencies.
What “full-stack” means in practice is end-to-end orchestration: consultancy and planning, land and power strategy, facility design, modular build, MEP integration, liquid cooling deployment, hardware integration, commissioning, and ongoing operations – which include edge compute nodes and the connectivity fabric required for low-latency inference. When one partner can coordinate these stages as a single program, TTT becomes a manageable system KPI rather than a sequence of handoffs.
Cooling strategy is a TTT decision
Cooling plays a critical role here, not as a facilities detail, but as a deployment decision. AI-era thermal loads are not merely higher, they have evolved: sustained utilization, concentrated hotspots, higher rack densities. It is why liquid cooling is no longer an add-on but a prerequisite for reliable AI infrastructure. The data centers that are liquid ready from the start use less, waste less and deliver more compute power compared to traditional air-cooled DC, while avoiding retrofits that could avoid expanding TTT and lower efficiency.
This is also where hybrid strategies matter. In many deployments, direct-to-chip liquid cooling addresses the most intense heat sources at the component level, while immersion or other liquid approaches can simplify systemic thermal management at rack level. The goal is not a single cooling method, but an architecture engineered for AI reality.
TTT meets “Intelligence per Watt”: speed is not enough
As AI moves deeper into the inference era and always-on workloads, efficiency becomes a constraint alongside speed. At Submer Group we call this “intelligence per watt” – system-level efficiency to maximize compute per unit of energy used across the full lifecycle. This means embedding sustainability into the engineering decisions that matter most, from power delivery and thermal design to how token produced are served and scaled.
The implication is important: rushing capacity online without designing for performance-per-watt will create long-term operational and economic penalties.
Efficiency also influences deployment decisions. Edge inference (smaller, specialized local processing) can reduce energy consumption significantly compared to running everything in centralized cloud facilities making the core-to-edge architecture not only a latency strategy, but an efficiency strategy too.
This reinforces why TTT should be measured across the whole platform, not only the core site.
Submer’s Time to Token playbook
This is where Submer Group’s execution model comes into focus. Time to Token shrinks when friction is removed across the entire chain. Submer Group’s approach combines four elements:
- Modular, scalable data center infrastructure delivered as repeatable blocks (reducing design churn and enabling predictable commissioning).
- Hybrid liquid-cooling reference designs that enable high-density AI deployments while supporting efficiency per watt across the lifecycle.
- Permitting-to-power orchestration: aligning land, power, approvals, supply chain, build, and commissioning under one accountable delivery model.
- Core-to-edge platform design: enabling localized inference nodes and resilient connectivity as part of one full-stack AI infrastructure plan.
The outcome isn’t just speed. It’s controlled speed: a program that comes online faster, scales more predictably, and remains efficient and sustainable as AI hardware evolves.
Time to Token is now a leadership metric
AI infrastructure has entered a phase where the limiting factor is no longer access to compute alone, but the ability to deliver it quickly and efficiently. Time to Token makes that reality visible. It forces alignment across strategy, procurement, engineering, and operations around a single objective: production output.
As AI ambitions intersect with sovereignty goals, expanding data center capacity, and growing edge inference needs, TTT is becoming a leadership metric. It is how organizations will judge whether a program is truly AI‑ready. Modular, liquid‑ready, full‑stack delivery is how that metric becomes achievable – bringing AI capacity online in months, not years, engineered as one integrated capability from the ground up.